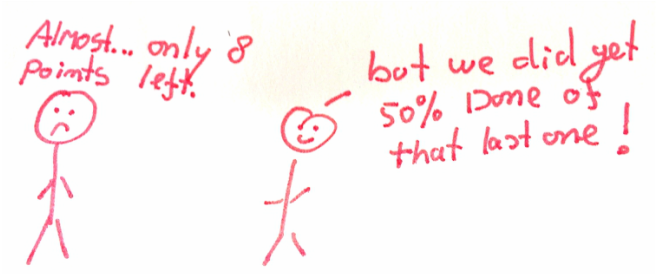In this post, I will try to explain why splitting stories sometimes causes a sort of waste.
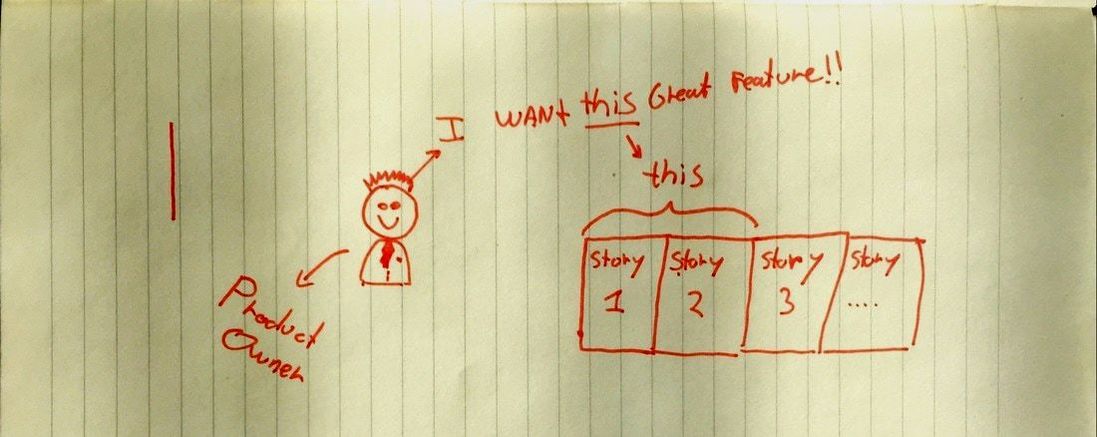
Let’s think of a situation where we have two stories in a sprint backlog that are related. There was a business requirement and it has been split in two small related stories. And when I say related…I really mean intensely connected with each other to a point that you can’t test it separately or it does not create any usable value if you release it separately. Only when build both, there is value and a happy customer.
Let’s think of a situation where we have two stories in a sprint backlog that are related. There was a business requirement and it has been split in two small related stories. And when I say related…I really mean intensely connected with each other to a point that you can’t test it separately or it does not create any usable value if you release it separately. Only when build both, there is value and a happy customer.
.
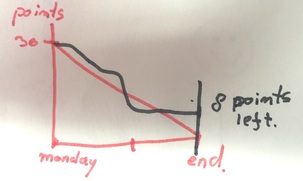
There are fundamental problems with related stories. First, you can’t test 1 story properly without the other, so 1 will never be done until the other one is also finished. On top of that, if there is an impediment for one the stories, the other is stalled too. With related stories, you are building a big risk in your sprint. And big stories will cause a flat line in the burn down chart. :(
How to split stories better?
When you have related stories, you probably split them wrong. There are several solutions and often splitting them a little different is already a solution. But sometimes splitting stories require additional extra work in your sprint.
There are fundamental problems with related stories. First, you can’t test 1 story properly without the other, so 1 will never be done until the other one is also finished. On top of that, if there is an impediment for one the stories, the other is stalled too. With related stories, you are building a big risk in your sprint. And big stories will cause a flat line in the burn down chart. :(
How to split stories better?
When you have related stories, you probably split them wrong. There are several solutions and often splitting them a little different is already a solution. But sometimes splitting stories require additional extra work in your sprint.
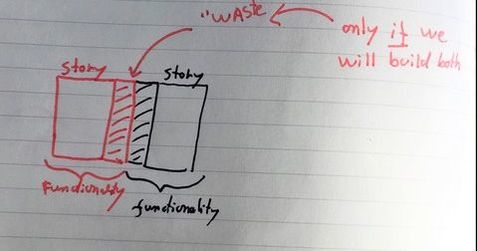
For example a contact form that should save to a CRM system. We created 2 stories for this. The form itself (story 1) and the save action to CRM (story 2). The stories are connected. They don't have much value on their own if we don't do anything.
To fix this you can add functionality to story 1 (e.g that it will save the info to disk) and for story 2 (that it will be a bit more generic solution with an API to the CRM, so other systems can also use it. )
Now they both have value on their own, there is no need to do them both but we are building more than we strictly should according the business requirement. (The integration part of the 2 stories is build in the story that we will pick up as latest.)
More work but less risk!
The only reason we put some extra effort in the two stories was to make them independent. It takes sometimes effort and extra work to do that. It seems a bit like waste but actually it really helps our process. In doing more work than we should, we are in fact creating more chance in delivering real value on time and lowering the risks of impediments! Hooray!
To fix this you can add functionality to story 1 (e.g that it will save the info to disk) and for story 2 (that it will be a bit more generic solution with an API to the CRM, so other systems can also use it. )
Now they both have value on their own, there is no need to do them both but we are building more than we strictly should according the business requirement. (The integration part of the 2 stories is build in the story that we will pick up as latest.)
More work but less risk!
The only reason we put some extra effort in the two stories was to make them independent. It takes sometimes effort and extra work to do that. It seems a bit like waste but actually it really helps our process. In doing more work than we should, we are in fact creating more chance in delivering real value on time and lowering the risks of impediments! Hooray!
Splitting stories…why are we doing that?
There are several good reasons why you want stories in your sprint to be small. I wrote an article about the traffic jam effect of big stories and you can also argue that large stories are inherent difficult to estimate so you will have problems in learning to estimate. In SCRUM, we are learning to drill down our work to good estimable little things to be as predictable as possible in time and quality.
When creating a story for a big request we try to split this in smaller stories with, in our team, the following rules:
There are several good reasons why you want stories in your sprint to be small. I wrote an article about the traffic jam effect of big stories and you can also argue that large stories are inherent difficult to estimate so you will have problems in learning to estimate. In SCRUM, we are learning to drill down our work to good estimable little things to be as predictable as possible in time and quality.
When creating a story for a big request we try to split this in smaller stories with, in our team, the following rules:
- It should be less than 13 points, smaller is better.
- It should be fully testable
- It should have value on its own
- It should be releasable on its own (because sometimes we fail in the sprint goal or the PO decides not to release something).